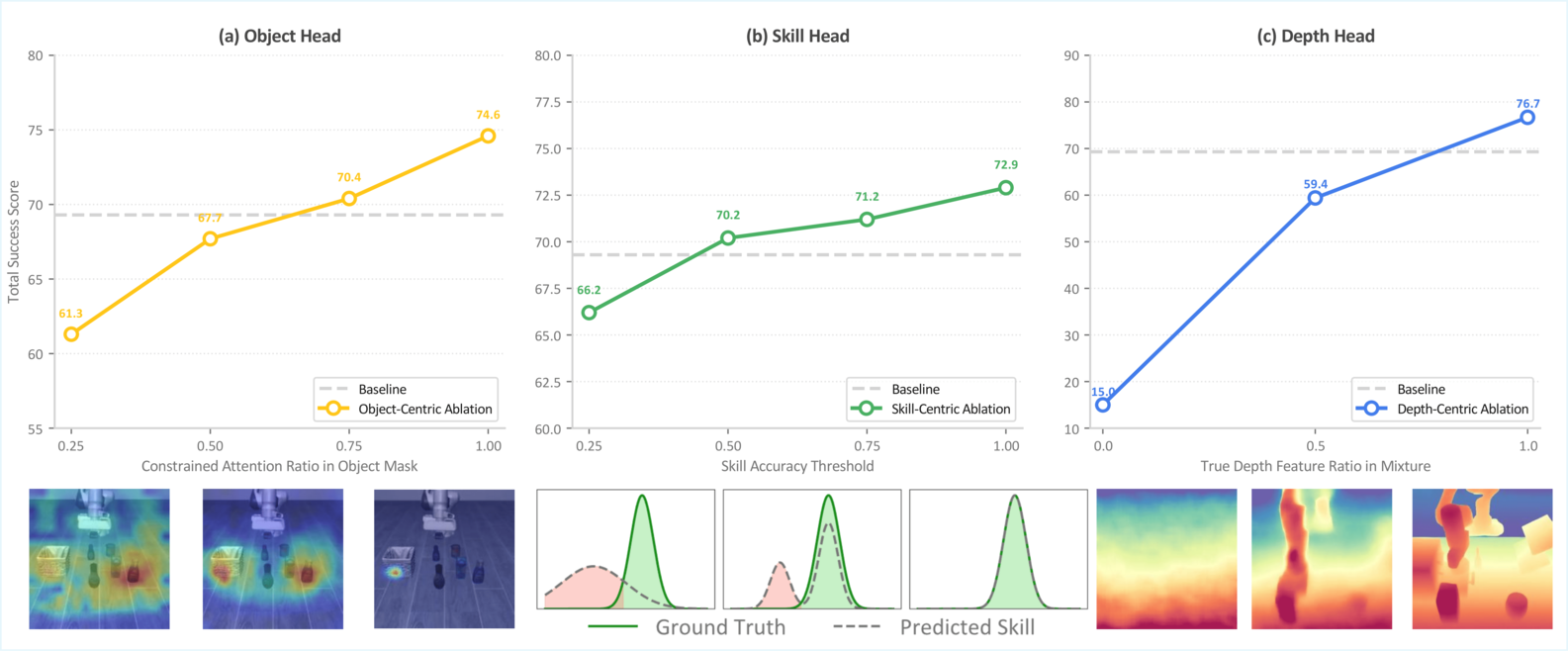
ABLATION: Factor Quality Correlation
Higher Factor Quality Leads to Better Task Performance. Top: Quantitative analysis on the LIBERO-Plus layout perturbation track shows that improving the quality of each specialized head consistently boosts success rates. (a) Object Head: as the proportion of attention focused on task-relevant object regions increases, success rises from 61.3% to 74.6%, highlighting the importance of precise object-centric attention. (b) Skill Head: higher skill-recognition accuracy, measured by a linear probe, correlates with improved performance (66.2% to 72.9%), indicating that better temporal understanding enhances control. (c) Depth Head: increasing the ratio of true depth features (versus noise) dramatically improves both qualitative depth estimation and quantitative success (15.6% to 76.7%), confirming that explicit 3D cues are critical for robust manipulation. Bottom: Qualitative visualizations show how changes along the x-axis metrics are reflected in the corresponding feature representations.